SGD란?
grdient descent를 할 때 데이터 전체를 전부 쓰는 것이 아니라
배치(데이터 전체보다 작은 규모의 데이터 세트)마다 한 번씩 update 하는 방법.
전체 데이터를 n 개의 배치데이터로 각각 분할하여 n 개의 set을 구성합니다.
그리고 각각의 배치데이터로 목적함수를 구성하여 목적함수를 최적화하도록
gradient descent로 w를 update 하는데 (그냥 gradient descent 과정..)
이때 각 배치데이터를 순회하며 목적함수를 계속해서 재구성합니다.
("재구성"이 중요합니다. update할때 목적함수를 계속 바꾼다.)
이거 왜 하는지
쉬운 이유로는 딥러닝에서는 데이터의 크기가 크면 layer가 깊어질수록
학습해야 하는 파라미터 수도 많아져 학습이 오래 걸린다.
작은 크기의 데이터를 반복적으로 학습하는 것이 더 효율적일 수 있다.
중요한 이유로는..
grdient descent의 문제로 항상 local min 문제가 있었죠,
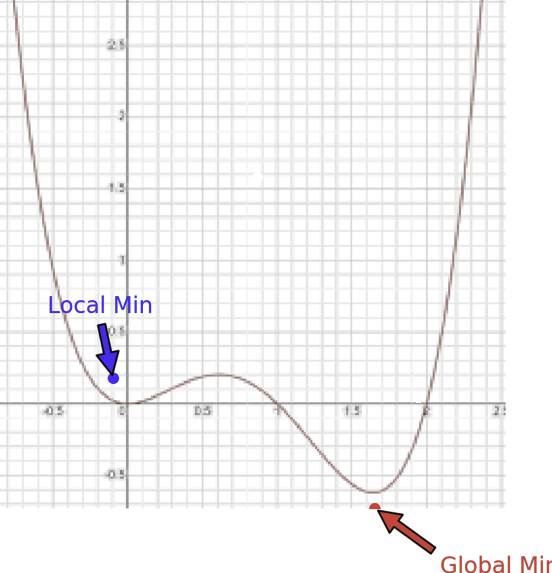
local에 빠지는 이유가 뭐였는지
gradient descent 식에서 gradient에 해당하는 부분 즉
loss 함수에 대한 미분 값에 해당하는 부분이

local point에서 0이 되면서 더 이상 update가 일어나지 않습니다.
즉 찾아야 할 global min으로 움직일 수 있는 "동력" 이 없다고 말할 수 있는데.
SGD를 사용하여 목적함수의 형태를 각각의 배치데이터로 계속해서 바꾸면
오른쪽 그래프처럼 loss 함수 자체가 계속 변화합니다.

이렇게 목적함수가 "변화" 하면 어떤 일이 일어날까요
첫 번째 배치데이터로 구성한 목적함수에서
local min에 빠져 gradient가 0이 되었다면
다음 배치데이터 구성한 목적함수는 함수가 달라 gradient 값이 0이 아닐 수 있음.
즉 local에 빠져도 특정 배치데이터에 대해서는 계속해서 update할 수 있는
동력이 있다고 볼 수 있습니다.
또 loss 함수가 다르기에 update 방향이 계속 변화합니다.
그래서 update 방향이 완전히 일정한 것은 아니지만
각 step에서 찾은 w의 값이 좌우로 움직이면서
점차 global min에 도달 할 수 있습니다.
결론적으로 local point에 멈추지 않고 근처의 global point라
할 수 있는 부분까지 update 할 수 있게 됩니다.
'인공신경망' 카테고리의 다른 글
| AdaGrad/RMSprop/Adam 이란? (2) | 2024.11.03 |
|---|---|
| 오버피팅(overfitting) 해결 및 방지 방법 (0) | 2024.10.29 |
| 역전파(Backpropagation)/vanishing gradient problem (0) | 2024.10.27 |
| MLP(multi-layer perceptron) (0) | 2024.10.15 |