Autoencoder란
Generative model을 구성하는 구조에 사용되는
또 다른 network 구조를 말합니다.
즉 Autoencoder란 그 자체로 생성 모델을 뜻하는 것은 아니며
생성 모델에 사용되는 별개의 network 구조라고 할 수 있습니다.
그래서 Generative model이 무엇인지 간단하게 먼저 살펴봅시다.
generative model의 학습 과정을 간단하게 아래와 같이 표현할 수 있습니다.
1. 입력 데이터로부터 데이터의 분포를 학습합니다.

가령 사람 얼굴 이미지 데이터 2000개를 input으로 넣으면
이 2000개 image가 어디로부터 왔는지
이렇게 추정한 분포로부터 이미지를 sampling하여
새로운 이미지를 생성하게 됩니다.
이때 추정한 분포가 이 세상에 존재하는 이미지 데이터의 분포와 유사하다면
마치 모집단의 분포를 알고 있는 거처럼
추정한 분포에서 계속해서 이미지를 생성해 낼 수 있습니다.
요약하자면 다음과 같습니다.
적당한 양의 이미지를 input으로 넣어 학습시키면
그럴듯한 이미지를 출력할 수 있는 분포를 학습하여
해당 분포로부터 이미지를 계속해서 생성할 수 있습니다.
이러한 모델을 generative model 이라 합니다.
다시 돌아와서 auto encoder란 무엇인지.
input data 그 자체를 복원하도록 회귀하는 network를 학습하는 모델입니다.
즉 loss 함수는 아래와 같이 출력값이 input data와 가까워지도록 합니다.

그 구조 자체에 대한 이해를 통해
AutoEncoder를 어디에 사용하며 왜 필요한지를 이해해봅시다.

위와 같이 어떤 입력 데이터 x가 주어지면 어떤 neural network를 지나
최종적으로 자기 자신을 예측하도록 output을 출력하는 구조를 가졌습니다.
더 자세히 보자면
network 안에는 encoder와 decoder 구조로 이루어져 있습니다.
encoder에서는 입력으로 받은 데이터 x에서 더 적은 차원으로의 z를 추출합니다.
decoder에서는 이 추출된 z에서 x라는 입력 데이터를 복원하는 과정을 거칩니다.

즉 이 decoder에서 x라는 input data를 잘 복원하려면 축소하여 추출한
z라는 feature가 핵심적인 특징들로 구성되어야 합니다.
왜그럴까요?
z로부터 decoder라는 network를 거쳐 output을 출력할 때
추출된 z가 input 데이터의 핵심 특징들이 아니라면
이 decoder의 network가 아무리 복잡한 구조이더라도
즉 decoder의 network가 이미지 복원을 위한 좋은 구조이더라도
절대 원래의 input data를 복원할 수 없습니다.
그래서 이런 autoencdor모델을 학습하는 이유..어디에 쓰는지?
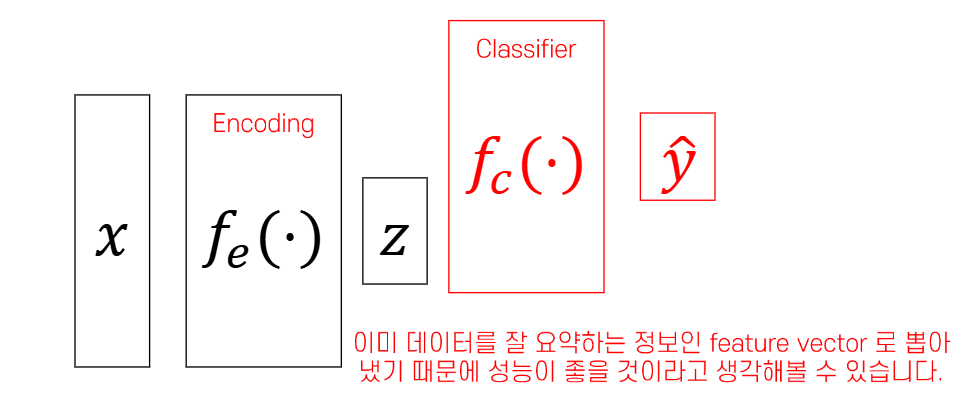
기존의 분류기의 학습 방식에서는
정답 값과 가까워지도록 loss 함수를 설정하고 gradient desecnt를 하면
local min에 빠질 수 있어 초기값을 다양하게 설정하기 때문에
학습 시간이 오래 걸렸으나
input data에 핵심 feature인 z를 이런 classifier에 초기값으로 넣게 되면
이러한 update 과정이 줄어들고 학습 초기부터 모델의 오차를 크게 줄일 수 있습니다.

이처럼 AutoEncoder는 원래 데이터의 차원 축소와 복원을 목적으로 설계되었으나
이후 생성 모델(generative model)의 핵심 구성 요소로 활용되고 있습니다.