일반적으로는 모델에 데이터 1개가 들어오면
그에 대응하는 output이 하나 출력됩니다.
가령 class 분류 문제에서 입력 데이터를 넣으면
대응되는 class 예측 값이 output으로 출력됐었는데.
입력 데이터가 하나가 아닌
시간 축을 따라 여러 개의 데이터가 순차적으로 들어온다면
그러한 데이터를 입력으로 받을수 있는 모델이 RNN입니다.
즉 RNN은 시간축에 따라 순차적으로 입력되는 데이터,
특히 대표적인 사례인 '시계열 데이터'를 효과적으로 처리할 수 있는 모델입니다.
Rnn은 데이터가 순차적으로 여러 개 들어올 때
output을 하나로 하는 many to one 문제
데이터가 순차적으로 여러 개 들어올 때
output도 그에 대응하여 여러 개 출력하는
many to many 로 구분할 수 있습니다.
그래서 rnn 구조를 자세히 봅시다.

우선 x1 x2 x3와 같이 시간에 흐름에 따라
입력 데이터가 순차적으로 들어온다고 했을 때
이전 layer의 hidden activity(h) 값도 입력으로 주어집니다.
즉 input이 x1과 같은 입력 데이터와 hidden 값으로 2개가 들어오게 됩니다.
이 들어온 입력값 두 개를 더해 활성화 함수에 집어넣으면
그 층에서의 hidden activity를 계산하게 됩니다.
그래서 기본적인 구조는 다음과 같이 요약할 수 있습니다.
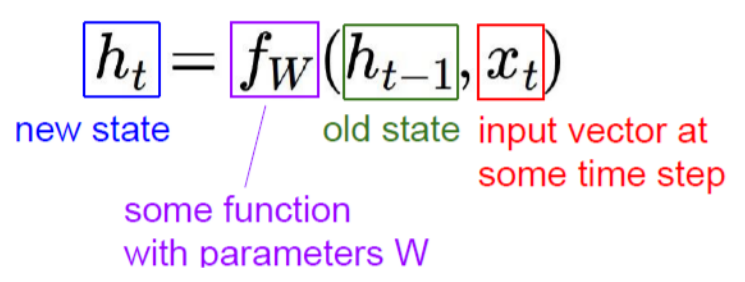
t라는 시점에서 t-1의 히든 값과 xt 시계열 데이터를 입력받아
활성화 함수를 거치면서 t 시점에서의 히든값을 얻어내게 됩니다.
구체적으로 입력값들을 어떻게 연산하여 처리하는지에 대해서..

t시점에서의 입력값으로 받은 히든 값 Ht와 입력 데이터 Xt에
각각 다른 weight를 걸어줍니다.
이때 히든 값에 계산하는 weight를 Whh
입력 데이터 계산하는 weight를 Wxh라 하겠습니다.
이렇게 weight를 걸어준 값을 더해 활성화 함수에 입력값으로 넣어줍니다.
이때 활성화 함수를 tanh를 사용합니다.
활성화 함수로 tanh 사용하는 이유로는,,
relu를 쓰면 입력값이 음수일 때 출력값이 0으로 값이 소실될 수 있습니다.
시그모이드를 쓰면 기울기의 최댓값이 0.2로
조금만 layer가 쌓여도 기울기가 vanishing 되는 문제가 생길 수 있습니다.
그러나 tanh는 전반적으로 그 기울기가 커서
vanishing 문제를 어느 정도 해결하며 값이 소실되는 문제도 막을 수 있습니다.
다시 돌아와서 ,Rnn의 전체 과정을 살펴봅시다.
만약 many to one 문제라면
즉 연속으로 들어오는 시계열 데이터에 대해
하나의 값을 output으로 출력하는 Rnn 모델이라면

앞서 본 방식대로 마지막 히든 값인 ht까지 구해놓고
이 ht에 마지막 weight인 Why를 선형결합하여 최종 output을 구할 수 있습니다.
이러한 히든층 ht는 시간축을 따라 들어온 x의 모든 값들을 고려한 값입니다.
(즉 마지막 activity는 시계열 데이터 전체를 반영하는 의미를 가지고 있습니다.)
따라서 Rnn은 이렇게 여러 개 들어오는 데이터를
요약하여 하나의 output을 출력할 수 있게 됩니다.
Rnn의 many to many 형태는 아래와 같습니다.

이번에는 히든 값이 결정될 때마다 그 히든 값에 Why 선형식을 걸어서
output을 계속해서 출력하는 형태입니다.
이때 rnn에서 weight는 모든 layer에서 같은 걸 씁니다.
예를 들면 여기서 Why는 어떤 layer에서든 같은 Why를 씁니다.
cnn과 유사하게 흐르는 시간에 따라 들어오는 데이터에 대해
동일한 특징을 계속해서 추출하기 위함이라 할 수 있습니다.
지금까지의 연산과정을 한눈에 보면 이와 같습니다.

이를 다른 방식으로 이해할 수 있습니다.
모든 layer에서 input으로 작용하는 이전 layer의 히든 값과 그때의 입력 데이터를
concat 연산하여 한 번에 같은 weight로 연산을 한다고 생각할 수도 있습니다.

Rnn에서의 역전파 방식.
Backpropagation through time이라는 걸 씁니다.
우선 앞서봤듯 t 시점에서의 ht와
many to one에서 최종 output은 아래와 같습니다.

이름은 다르지만 연산 방법은 기존의 backpropagation 방식과 크게 다르지 않습니다.
가령 최적화 대상이 되는 loss함수가 있다고 생각해 봅시다.
이 loss를 히든 activity에 걸어주는 Whh에 대해 update 해야 한다고 생각해 봅시다.
그럼 아래와 같이 쓸 수 있습니다만..

사실 여기서 ht는 이전의 히든 activity인 h(t-1)로 이루어진 함수이고
이 h(t-1)도 whh로 이루어져 있습니다.
따라서 h(t-1)도 whh로 미분할 수 있습니다.
즉 아래처럼 시간에 따라 0번째까지 미분해서 gradient를 계속해서 계산할 수 있습니다.

'RNN(Recurrent neural network)' 카테고리의 다른 글
| Seq2seq 및 attention mechanism (4) | 2024.12.09 |
|---|---|
| Multilayer RNN, biRNN(bidirectional)이란? (0) | 2024.12.08 |
| RNN 기반 언어모델 (0) | 2024.12.08 |
| LSTM(Long Short Term Memory) (0) | 2024.12.07 |