seq2seq의 목적과 구조에 대해 이해해 보고
seq2seq에 attention mechanism을 적용해 봄으로써
attention mechanism이 무엇인지 의도와 방식을 이해해 봅시다.
seq2seq란?
주로 번역에 쓰이는 다음 단어를 예측하기 위한 모델입니다.
seq2seq 모델은 RNN 또는 lstm모델에 기반하는데
단순한 RNN의 구조로도 다음 단어를 예측할 수 있는 모델을 구성할 수 있었습니다.
그래서 단어를 예측하는 단순한 RNN의 구조를 간단하게만 먼저 살펴봅시다.

위에서 볼 수 있듯이 전 cell에서의 출력값을 input date로 입력하면
출력값으로 다음 단어가 나오고 이 값을 다시 다음 cell의 input으로 입력하는
과정을 반복해서 최종 정답 값을 output으로 출력하는 구조였습니다.
- (자세한 내용참고)
2024.12.08 - [RNN(Recurrent neural network)] - RNN 기반 언어모델
RNN 기반 언어모델
RNN이란?2024.12.05 - [RNN(Recurrent neural network)] - RNN(Recurrent neural network)이란? RNN(Recurrent neural network)이란?일반적으로는 모델에 데이터 1개가 들어오면 그에 대응하는 output이 하나 출력됩니다.가령 clas
tmddn0512.tistory.com
그런데 번역이란 문제에서는 어떨까요
번역에서의 가장 큰 문제가 되는 점은 바로 언어의 어순입니다.
즉 번역하고자 하는 언어와 기존의 언어가 어순이 다르다면
위와 같은 방식으로는 다음 단어를 예측할 수 없습니다.
따라서 번역이 필요한 문장을 한번에 다 축약해서 받아들이고
이 축약된 정보를 어순에 맞게 번역을 진행하는 식의 구조가 필요합니다.
이때 전자를 encoder 후자를 decoder 형태로 구현한 것이
바로 seq2seq입니다.
그래서 seq2seq의 구조를 살펴봅시다.

encoder 영역에서 우선 time series data를 입력으로 받습니다.
이때 many to one 구조이며 기존의 lstm 연산 방식과 완전히 동일합니다.
즉 장기기억으로 처리할 정보 cell state와 기존의 정보를 통해 계산한
hidden activity를 계속해서 다음 cell의 input으로 참여시킵니다.
즉 간단하게 수식으로는 아래와 같습니다.

여기서 중요한 것은 lstm의 연산은 rnn과 유사하게 해당 시점에서의
input data와 이전층의 hidden 값 그리고 장기기억인 cell state를 input으로 받아
현재 시점에서의 hiden 값을 계산한다는 것입니다.
즉 모든 입력 데이터가 계속해서 hidden 값을 계산하는 데 사용되기에
encoder의 최종 lstm의 hidden 값은
번역하고자 하는 문장의 축약된 정보로 이해할 수 있습니다.
이 축약된 정보이자 encoder의 마지막 lstm의 hidden 값을 context vector라 합니다.
이제 context vector를 번역이라는 의도에 맞게 decoder에서
풀어 내는 것입니다.
이 decoder 구조를 살펴봅시다.

번역하고자 했던 문장은 " i am a student "였습니다.
즉 "i"를 번역하여 "je"라는 값이 출력돼야 하는 상황입니다.
이를 위해 decoder의 첫 번째의 input으로 start of sentence를 입력합니다.
즉 output으로 "je"가 나올만한 적절한 값을 줬다고 생각해 봅시다.
그럼 RNN의 기본적인 언어 모델과 같은 방식으로
전 cell의 출력값인 "je"를 다음 cell의 input으로 입력하고
"am"에 해당하는 "suis" 라는 단어가 출력값으로 나오길 기대합니다.
즉 이런 식의 구조로 모델이 구성되면 decoder의 출력값으로
번역은 물론 student의 해당하는 etudiant의 다음 단어도 예측할 수 있게 됩니다.
그런데 사실 이러한 모델이 필요하다는 것이지
이것이 seq2seq의 학습 방식이 아닙니다.
따라서 위와 같은 구조로 작동하기 위한 학습은 어떻게 진행해야 하는지.
학습이 안된 상태에서 decoder의 input으로 단어를 무작정 집어넣으면
그냥 이상한 값이 나오게 될 것입니다.
그래서 위아래로 정답 값을 입력하여 학습합니다.
이게 teacher forcing 방식.
즉 input에도 정답을 넣고 그때 출력으로 나와야 하는 값으로 정답 값을 넣습니다.
이렇게 올바른 값을 출력하도록 하는 weight를 학습시킵니다.
attention mechanism
앞서본 seq2seq 모델에 attention을 적용하여
attention 이란 무엇이고 왜 필요한지 확인해 봅시다.
다시 seq2sqe 모델을 보면
decoder의 출력값을 결정하기 위해서 context vector의 값을 이용했었습니다.
이때 "je"라는 값이 출력되려면 번역이라는 문제에서는
"je"라는 언어에 대응하는 "i"라는 정보가 가장 중요할 것입니다.
그런데 "i"가 encoder에서 초기에 주어졌기 때문에
encoder의 마지막 cell의 hidden activity인 context vector에는
"i"라는 정보가 소실되어 있을 수 있습니다
즉 lstm을 사용하더라도 순방향 문제 때문에
본질적으로 long term dependency 문제가 발생합니다.
그래서 encoder에서 발생하는 각각의 output을 중요도에 따라 반영하여
context vector를 구성하자는 것입니다.
attention의 연산 구조를 대략적으로 살펴봅시다.

즉 이와 같이 decoder에서의 어떤 출력값을 결정할 때
초기 정보가 사라진 기존의 context vector만을 사용하는 것이 아니라
encoder에서의 출력값을 중요도에 따라 가져와서 context vector를 구성하고
그 context vector로 decoder의 출력값을 결정하자는 겁니다.
구체적으로 예시를 들어보겠습니다.

위와 같이 "etudiant"를 예측해야 하는 상황이라고 해봅시다.
이때 encoder에서 "student"를 input으로 넣었을 때 output으로 발생하는
hidden activity (h4)를 많이 가져와서 context vector를 구성하자는 겁니다.
왜냐하면 "etudiant"를 예측하는데 대응되는 "student"가 중요한 것은 자명합니다.
그런데 이 중요도를 어떤 식으로 결정할지 생각해 봅시다.
attention score: 이 중요도를 계산하는 방식은 많습니다만

여기서는 간단하게 내적을 사용합니다.
우선 내적의 기하학적 연산을 봅시다.
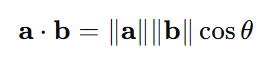
즉 두 벡터가 이루는 각이 0에 가까울수록, 유사도가 높은 단어일수록
embedding에 의해 공간상에서 두 단어가 이루는 각이 0도에 가까워집니다.
즉 cos 값은 1에 가까워지고
두 단어가 연관성이 없어 벡터가 90도에 가깝다면 cos 값은 0에 가까워집니다.
즉 이러한 내적 연산이 embedding된 벡터들의 유사도를 측정하기에 좋은 수단이 됩니다.
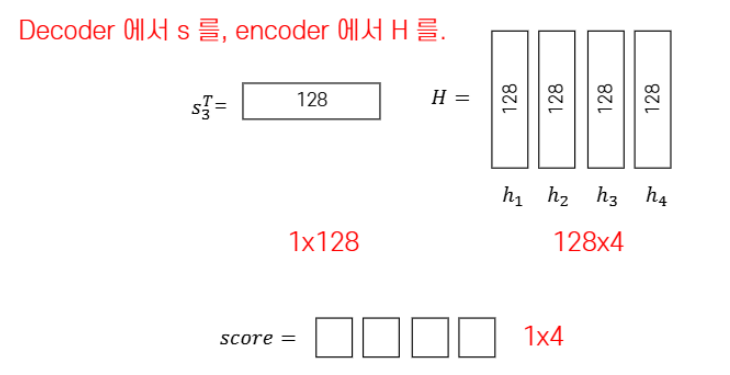
그래서 attention score의 계산 예시를 들어봅시다.

위에서 보는 거와 같이 decoder에서의 출력값을
encoder에서의 각각의 출력값에
내적 연산을 진행합니다.
여기서 중요한 점은 내적 연산이 성립하려면 위에서 보는 거와 같이
내적 연산에 참여하는 두 벡터의 크기가 같아야 합니다.
그런데 현재 내적의 대상인 decoder에서의 출력값과 encoder에서의 출력값은
tanh 활성화 함수를 거쳐 나온 값입니다.

즉 tanh 함수의 출력값은 -1과 1 사이로 출력값의 상한과 하안을 알고 있습니다.
따라서 encoder에서의 출력값과 decoder에서의 출력값의 크기가 비슷할 것이라는 겁니다.
그래서 rough 하게 내적으로 유사도를 측정 할 수 있습니다.
이제 내적 값을 아래와 같이 구했다고 한다면
아래와 같이 구한 내적값을 softmax 함수에 넣어 계산합니다.

이제 이 값을 attention의 weight로 사용할 수 있습니다.
즉 유사도 큰 두 단어 사이의 내적 값은 커지고 softmax의 값이 커져
attention score가 크게 할당됩니다.
1. 이렇게 구한 값을 attention weight로 하여
2. decoder의 hidden 값 각각에 곱하여 전부 더합니다
3. 이 값은 context vector의 일부가 됩니다.

context vetor의 일부를 얻어낸다고 표현하였는데
위에서 구한 값을 decoder의 마지막 cell에서의 hidden 값인
기존의 context vector와 concat 연산을 하여
단어의 유사도에 따라 중요도를 반영한 최종 context vector를
아래와 같이 얻어내게 됩니다.

최종적으로 이 context vecetor를 통해 중요도를 반영하여
"etudeiant"라는 단어를 출력할 수 있게 됩니다.
'RNN(Recurrent neural network)' 카테고리의 다른 글
| Multilayer RNN, biRNN(bidirectional)이란? (0) | 2024.12.08 |
|---|---|
| RNN 기반 언어모델 (0) | 2024.12.08 |
| LSTM(Long Short Term Memory) (0) | 2024.12.07 |
| RNN(Recurrent neural network)이란? (0) | 2024.12.05 |