seq2seq 모델을 간단하게 살펴봄으로써 attention-mechanism을 이해한 후
self-attention을 이해해 봅시다.
언어 모델을 "번역"이라는 task에 사용한다면 transformer 이전에는
RNN 혹은 LSTM을 기반으로 한 모델에 attention-mechanism을 적용한
seq2seq 모델을 활용했었습니다.
seq2seq 및 attention-mechanism
2024.12.09 - [RNN(Recurrent neural network)] - Seq2seq 및 attention mechanism
Seq2seq 및 attention mechanism
seq2seq의 목적과 구조에 대해 이해해 보고 seq2seq에 attention mechanism을 적용해 봄으로써 attention mechanism이 무엇인지 의도와 방식을 이해해 봅시다.seq2seq란?주로 번역에 쓰이는 다음 단어를 예측하
tmddn0512.tistory.com
seq2seq 모델의 구조는 아래와 같습니다. (기존 모델의 문제점부터 봅시다.)

seq2seq에서는 다음 step의 input으로 time-series-data뿐만 아니라
전 layer에서 계산된 hidden vector도
계속 다음 step에 input으로 작용했었습니다.
이 구조 때문에 모델이 깊어질수록
초기에 들어온 input이 점점 희미해지는 본질적인 문제 long term dependency를
attention-mechanism으로 완전히 해결 할 수 없습니다.
그래서 transformer에서는 attention-mechanism을 사용하지만
long term dependency 문제를 해결할 수 있는 self-attention을 사용하게 됩니다.
seq2seq에서 사용한 attetion-mechasim을 간단히 살펴보겠습니다.
self-attention에서는 input으로 들어오는 하나의 data가
query, key, value 로써 3개의 역할을 수행하게 됩니다.
여기서 query와 key, value는 무엇인가?

위에서 볼 수 있듯, 하나의 Decoder Hidden State와
각각의 Encoder Hidden State를 내적하여,
Decoder Hidden State를 기준으로 한 각 값의 유사도를 계산했습니다.
이후 이 내적값에 softmax를 취해 얻은 attention을 얻어내어
encoder hidden state 각각에 attention을 곱해 전부 더하여
context vetor를 얻는 식이었습니다.
그래서 query는 무엇인가?
유사도를 구할 때 무엇과의 유사도를 구하고 있는지 생각해보면
자명히 decoder의 hidden state임을 알 수 있습니다.
이처럼 유사도의 기준이 되는 decoder의 hidden state를 query라 하며
그리고 이 query와의 내적의 대상이 되는 각각의 값들을 key라 합니다.
즉 각각의 encoder의 hidden state를 말하며
최종적으로 attention 값을 encoder의 hidden state에 곱할 때 사용되는
encoder의 hidden state들을 value라 합니다.
(따라서 encoder의 hidden state들은 역할에 따라 key와 value로 불릴 수 있는 것입니다.)
self-attention
self-attention에서는 input으로 들어오는 하나의 data가
query, key, value 로써 3개의 역할을 수행하게 된다고 하였습니다.
즉 하나의 input에 대응되는 3개의 vector를 계산하게 되고
이 각각의 3개의 vector가 query, key, value 로써의 역할을 하게 됩니다.
따라서 input data는 query로써 역할은 물론 동시에 key 와 value로써 역할을
수행한다는 점에서 self-attention이라 할 수 있습니다.
즉 input 자기 자신이 유사도를 구하는데 기준이 되기도, 대상이 되기도 한다는 것입니다.
이 하나의 input에 대응되는 3가지 행렬을 계산할 때에는
서로 다른 weight 행렬 연산을 적용하여 아래와 같이 계산하게 됩니다.

가령 아래와 같이 input이 2개가 들어온 경우를 살펴봅시다.
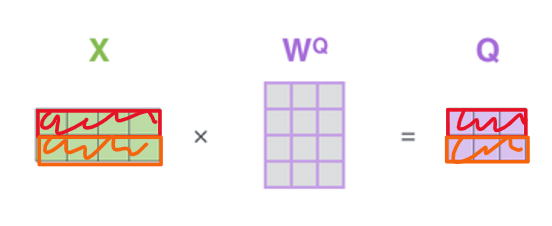
이렇게 각 행마다 하나의 input을 의미하며 이때 query 역할을 하기 위해
Wq 행렬로 weight 연산을 해주어 결과로 query 행렬을 얻습니다.
여기서 중요한 점은 결과로 얻어지는 행렬의 각각의 행은
각각의 input에 대응되는 값이라는 겁니다.
즉 결과행렬의
첫번째 행은 첫번째 input에 대응되는 값
두번째 행은 두번째 input에 대응되는 값.
이런식으로 query, key, value 행렬을 구성하게 됩니다.

그다음 과정은 seq2seq의 attetion을 구성하는 과정과 같습니다.
seq2seq에서는 query 역할을 하는 decoder의 hidden state 값을
각각의 encoder의 hidden state 값인 key에 내적하여 유사도를 구했었습니다.
마찬가지로 각각의 쿼리를 기준으로 나머지 key 값들에 내적을 수행하게 됩니다.

위의 계산을 수행하게 되면 결과 행렬의 첫 번째 행에는
Q1을 기준으로 한 나머지 값들의 내적 값이 계산되어 있습니다.
여기서 다시 집고 넘어갈 점은
K1은 Q1과 마찬가지로 첫 번째 input data에 대응되는 것이기에
자기 자신에 대한 attention을 계산하는 과정이 포함되어 있다는 것입니다.
이제 이 결과로 나온 행렬에 각각의 행마다 softmax를 씌워준다면.
각 행에는 각 query에 대응되는 attention 값이 구성됩니다.
가령 이런 식으로 구성됩니다.

(1행에는 q1을 기준으로 한 attention score
2행에는 q2을 기준으로 한 attention score가 계산되어있습니다.)
이제 이 attention score를 가중치로 하여 해당 가중치만큼 value를 가져오기 위해
attention score를 value와 곱하게 됩니다.
(즉 중요도 만큼 value를 가져오자는 attention mechanism)
지금까지의 최종과정을 요약하자면 아래와같이 표현할 수 있습니다.

1.query 행렬과 key 행렬의 내적을 softmax에 넣어 attention 구하기
2.구한 attention을 value와 곱 연산
최종적으로는
z에 첫 번째 행에는 q1을 기준으로 구한 유사도를 반영하여 value를 가져온 값이
두 번째 행에는 q2를 기준으로 구한 유사도를 반영하여 value를 가져온 값을 얻어내게 됩니다.
여기서 dk로 나누어주는 과정이 있습니다.
dk는 무엇이고 왜 나누어야 하는지?(Scaled Dot-Product Attention)

dk는 위와 같이 query 와 key 행렬의 열 space의 차원을 의미합니다.

이 dk는 위에서 볼 수 있듯 입력데이터에 걸어주는
weight 행렬의 열 space 차원에 의해 결정됩니다.
(wq의 열이 3개면 query vetor 열이 3개)
다양한 특징을 잡기 위해서나 혹은 size를 맞추기 위해서 등등 여러 이유 때문에
weight의 열 space 차원을 키우면 query, key vector 차원이 커지게 되고
이렇게 되면 내적 값의 분산이 커질 수 있습니다.
내적 값의 분산이 커진다는 것은..
내적의 값이 나오는 범위가 어떻게 될까를 생각해 보자는 겁니다.
쉽게 생각하면 내적 값 자체를 마치 확률 변수처럼 생각해 볼 수 있습니다.
이러한 확률 변수의 값의 범위를 예측해 보자는 것은
결국 분포에 대한 추정과 같아지며 그것은 분산을 생각해 보자는 것과 같습니다.
이 내적 값의 분산은 차원의 크기와 비례합니다.
가령 dk가 10이라 한다면.

내적의 분산은 위의 식처럼 계산되게 됩니다.
즉 차원이 커지면 최종적으로 분산이 커지게 됩니다.
이게 문제가 되는 이유
내적의 값은 attention을 구하기 위해
최종적으로 softmax의 input으로 넣었습니다.

softmax식 특성상 분자에 지수함수가 있어 z 값이 조금만 커져도
그때의 output이 매우 커질 수 있습니다.
예시를 들어보겠습니다.

위에서 "2. 분산이 큰 경우" 와 같이 출현하는 값들 사이의 편차가 커진다면
z값이 평균으로부터 많이 떨어진 값이 나올 수 있습니다.(가령 위에서는 10)
그때의 값은 softmax를 거치게 되면 그 값만 1에 가까워져
하나의 변수만 선택하도록 하는 attention 결과가 구성되게 됩니다.
이는 중요도에 따라 value 값을 적절하게 반영하는 기능을 잃을 수 있다는 것을 의미합니다.
이 문제를 내적 할 때에 dk 즉 차원의 크기로 나눠 줌으로써 방지할 수 있게 되는 것입니다.
'Transformer' 카테고리의 다른 글
| Transformer : encoder 및 decoder (Masked Self-attention) (0) | 2025.03.01 |
|---|---|
| Transformer : Multi-head Attention (Add & Norm) (0) | 2025.02.24 |