self-attention 연산과정에 대한 이해를 기반으로
Multi-head Attention이 무엇인지
Add&Norm 연산은 무엇인지 정리합니다.

즉 위의 한 블럭을 이해하는 것을 목표로 합니다.
self-attention은 무엇이었는지?
2025.01.22 - [데이터 마이닝] - Transformer란? (self-attention)
Transformer란? (self-attention)
seq2seq 모델을 간단하게 살펴봄으로써 attention mechanism을 이해한 후self attention을 이해해 봅시다. 언어 모델을 "번역"이라는 task에 사용한다면 transformer 이전에는 RNN 혹은 LSTM을 기반으로 한 모델
tmddn0512.tistory.com
Multi-head Attention이란?
transformer에서는 input을 query, key, value로써 역할을 수행하도록
각각의 역할에 대응하는 Wq, Wk, Wv의 weight matrix와의 곱을 했었습니다.

그런데 Wq라는 하나의 matrix는 하나의 특징으로만 input을 처리할 수 있습니다.
가령 cnn을 생각해 봅시다.
cnn은 weight matrix로 이루어진 filter를 사용하는데
이 filter의 종류에 따라 포착할 수 있는 시각적 특징이 달라지기에
다양한 특징을 출력하기 위해서 filter를 여러 개 사용했었습니다.
마찬가지로 이 Wq와 같은 weight matrix를 하나만 가져가는 것보다
다양한 특징과 기준으로 정보를 처리하도록
여러 개의 weight matrix를 사용하자는 것입니다.
그래서 이 Wq, Wk, Wv의 다양한 종류의 matrix를 병렬적으로 적용합니다.

이때 Wq, Wk, Wv에 의해 각 query,key,value가 계산되면
이후 self-attention의 결과로 아래와 같이 z vector가 계산되었었습니다.
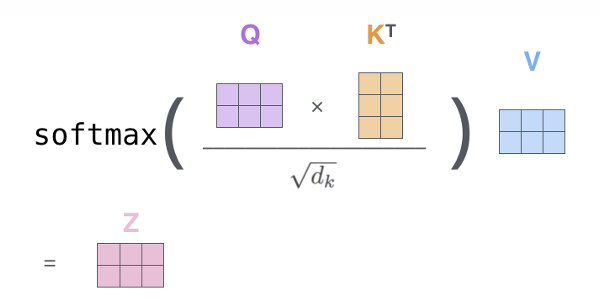
따라서 이런 weight matrix의 종류 만큼 z도 생성되게 됩니다.
가령 weight maritx를 각각 다른 종류 7개의 set을 사용해서 z를 구한다면
아래와 같이 7개의 z가 나오게 됩니다.
이후 여러 개 나온 z를 concat 하게 됩니다.

이후 이렇게 차원이 커진 concat 된 z를 또 다른 weight matrix와의 선형연산을 통해
최종 z를 원하는 size로 계산합니다.
여기까지의 과정을 한 번에 표현하자면 아래와 같습니다.

즉 각기 다른 weight matrix에서 처리한 z를 concat하여 W0 maritx와의
선형 계산을 통해 원하는 차원으로 최종 z를 얻을 수 있습니다.
즉 다양한 기준 및 특성을 반영한 최종 z를 원하는 size로 얻게 되는 것입니다.
후에 다시 언급하겠지만, 여기서 최종 z는 처음 input 데이터와 size를 일치시킵니다.
이는 skip connection을 사용하기 위함입니다.
즉, 이 최종 결과에 input data 자체를 더해주는 연산을 가능하게 하기 위해
input data와 차원을 같게 하는 것입니다.
Add & Norm
위에서 본 Multi-head-attention을 지나 Add& Norm이라는 연산을 거치게 됩니다.
앞서 봤듯 multi-head-attention 결과로 나온 z는
input과 size가 같아져 skip connection을 활용할 수 있습니다.
skip connection이란?
layer를 거친 output에 layer를 거치지 않은 input 그 자체를 더하는 것을 말합니다.
왜 이렇게 하는지?
각 feature마다 optimal depth가 다를 수 있습니다.
즉 미리 추출된 중요 feature가 layer를 거치면서 오히려 그 의미가
퇴색되는 것을 막을 수 있으며 전체적인 loss 함수를 smooth 하게 바꿔줄 수 있습니다.
그래서 self-attention 결과로 각 단어에 대응되는 encoding된 vector를 얻어내면
해당 vector에 input data를 더하는 과정을 "Add" 에서 수행합니다.

self-attention을 통해 "thinking" 과 "machines" 이라는 단어에 대응되는
encoding된 vector을 얻어 이 vector에 skip connection 연산까지 진행했다 합시다.
이후 데이터 사이의 절대적 차이가 아닌 상대적 차이를 학습하기 위해 정규화를 진행해 줍니다.
가령 아래와 같이 인코딩 된 vector의 값의 분산과 평균을 정규화 합니다.
이는 모델의 학습이 안정화되며 학습이 잘 진행되도록 합니다.

이러한 Add & Norm 연산 이후에
이 연산 결과를 input으로 feed foward 라는
동일한 fully connected layer를 거치게 합니다.
이렇게 또 다른 선형변환을 통해서 input과 같은 차원의 벡터가 만들어지고
거기에 다시 정규화 및 residual(skip connection)을 적용하여
각각에 단어에 대응되는 encoding된 벡터를 계속해서 얻어냅니다.
Transformer: Positioning Encoding

transformer는 long term dependency 문제를 잘 처리합니다.
왜일까요?
가령 Rnn에서는 attention을 쓰더라도
결과를 내는 과정에서는 순차적 연산 구조를 따를수 밖에 없습니다.
그런데 Transformer는 Self-Attention 메커니즘을 통해 모든 토큰 간의 관계를
한 번에 병렬적으로 계산합니다.
각각을 key로 query로 value로 병렬적 연산을 하기에
순차적 구조를 따르지 않아 본질적인 long term dependency 문제를 해결할 수 있습니다.
정리하자면..
RNN은 데이터가 순차적으로 들어오는 구조와 동일한 방식으로 처리되지만
Transformer 과정은 각 토큰이 다른 토큰들과의 관계를 계산하므로, 각 토큰 간의 연산이 독립적입니다.
즉 연산 자체의 병렬적 처리가 가능한 구조라는 겁니다.
그런데 병렬적으로 처리하는 만큼 각 순서에 대한 정보가 사라지게 됩니다.
즉 입력 토큰 간의 관계를 학습하지만 위치 정보를 직접적으로 포함하지 않습니다.
따라서 위치정보 즉 input의 순서 정보를 encoding 하여 표시해 줄 필요가 있습니다.
따라서 벡터 차원수만큼 그래프를 도입하여 위치정보를 담고 있는 벡터를 만듭니다.
가령 input 벡터가 4차원이라면 아래와 같이 input data에 대응하는 위치정보를
담고 있는 벡터를 만듭니다.

이후 이 값을 벡터로 만들어 input 벡터에 아래와 같이 더해주게 됩니다.

이렇게 더해진 결과는 "단어 의미 정보 + 위치 정보"를 동시에 가지게 됩니다.
이러한 Positioning Encoding 과정으로 순서 정보를 처리할 수 있게 됩니다.
self-attention 시각화

이와 같이 각 단어를 query로 하였을 때 attention을 어디에 두었는지 시각화하여
해당 단어를 예측하는데 어떤 단어가 중요한지 직관적으로 확인해 볼 수도 있습니다.
'Transformer' 카테고리의 다른 글
| Transformer : encoder 및 decoder (Masked Self-attention) (0) | 2025.03.01 |
|---|---|
| Transformer란? (self-attention) (0) | 2025.01.22 |