cnn이란?
CNN(Convolutional Neural Network)이란,
이미지나 영상 데이터를 처리하고 분석하는 데 주로 사용되는
인공 신경망의 한 종류입니다.
왜 출현하게 됐는지 정확하게 cnn으로 하고자 하는 게 무엇인지 살펴봅니다.
만약 아래와 같은 이미지 데이터가 존재한다고 할 때
기존의 mlp에서는 어떻게 이미지 데이터를 학습했었는지 살펴보면

각각의 픽셀별로 이미지 데이터를 분할하여
(w) 파라미터를 전부 곱하고 더해 학습했었습니다.
즉 2차원의 데이터를 픽셀 단위로 분할하여
데이터를 flatten 하여 입력했었습니다.
그런데 이게 시각적 정보를 처리하는데 비효율적입니다.
'6'이라는 시각적 정보를 전혀 활용하지 않고
잘게 분할하여 학습을 시키는 거와 같습니다.

위에서 볼 수 있듯이 2차원에서 시각적 이미지로 판단하면
( 0? 6? 8?) 숫자임을 알 수 있는데
이걸 픽셀 단위로 쪼개면 이러한 시각적 정보를 완전히 잃게 됩니다.
그래서 이러한 시각적 정보를 그 자체로 기계학습에 이용하려 하는 방식이
CNN입니다.
시각적인 정보를 기계가 어떻게 받아들이고 학습할 건지에 대해.
방법으로 동물의 시각 정보처리 과정을 모방합니다.
동물의 시각 정보 처리는 어떻게 이루어지나요

망막 신경에 존재하는 뉴런에는 정보를 받아들이는 영역이 존재합니다.
가령 위의 예시처럼 어떤 뉴런들은
대각선 영역에 빛이 들어와야만 활성화되는 거처럼
뉴런을 활성화시키는 영역이 존재하는 것이죠
우선 이 활성화 영역이란 개념을 모방합니다.
또 인간의 시각 정보처리 과정을 더 살펴봅시다.

v1에서는 선이라는 시각적 정보에 대해 활성화되는 뉴런이 있고.
v2에 뉴런은 모양, 면에 의해 활성화되는 영역이 존재하고
V4에는 오브젝트에 의한 활성화되는 뉴런이 존재합니다.
It에 있는 뉴런들은 사람 얼굴에 대해 활성화됩니다.
여기서 중요한 것은 정보를 그룹으로 묶어서 하나로 축약하고
점을 묶어서 선으로 선을 묶어서 오브젝트로 계속해서
시각적인 특징들이 점점 묶어서 발전하는 방식으로 돼있더라는 것입니다.
그래서 이러한 방식을 모방해서 기계를 학습한다면
2차원 이미지를 학습할 수 있다는 거죠.
이것을 어떻게 cnn에서 구현하는 지 살펴봅시다.
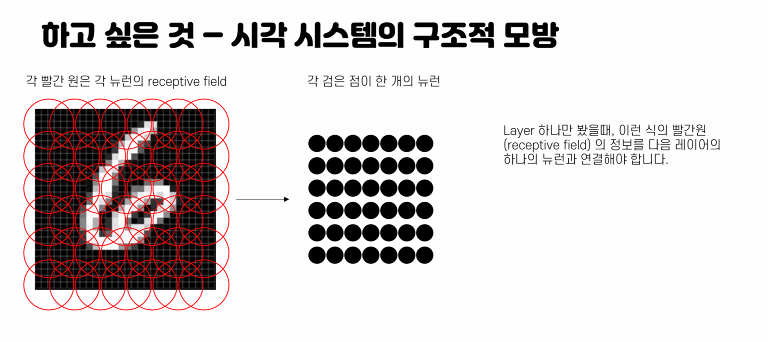
망막에 있는 각각의 뉴런들은 감지하고 있는 각각의 영역들이 존재할 것입니다.
이러한 영역들을 receptive field 라 부릅니다.
이러한 field안에서는 특정 영역 안쪽에 빛이 있으면
활성화되고 빛이 없으면 활성화되지 않는 영역이 존재하며
이것을 weight들의 값을 다르게 함으로써 구현할 수 있습니다.
이 과정을 자세히 하나의 receptive field 안에서 살펴보면..

receptive field 안에서 각각의 픽셀 값에 각각의 w를 곱하고 더해 ouput을 구성하고
그 값을 활성화 함수에 넣어 이 receptive filed에 대응되는 최종 ouput을 구성합니다.

이런 식으로 다른 receptive filed에 대한 연산도 반복하게 되는데,
이때 이러한 모든 연산에 동일한 w(weight)를 사용합니다.
이게 무슨 의미일까요?
모든 receptive field에서 같은 기준(weights)에 따라 정보를 처리하고 싶다는 겁니다.
가령 이미지의 대각선 특징을 추출하고 싶다면 대각선 위치에 있는 weight를 크게
나머지 영역의 weight는 작게 처리합니다
따라서 어떤 field안에 대각선의 놓여있는 픽셀 값이 크다면
그 영역에서의 최종 ouput을 크게 가져가고
해당 field에는 찾고자 하는 특성이 강하게 존재한다는 정보를
다음 layer에 전달해 주는 것이죠.
이런 식으로 각각의 receptive field에서 축약한 정보 하나를
다음 layer의 하나의 원소로 구성해 나갑니다.


이때 사용한 w1~wk(weights)를 filter라 부르고
이러한 filter를 모든 receptive field에 동일한 구성으로
가져가면서 동물 세포의 시각 정보처리 과정을 모방 할 수 있게 됩니다.
이러한 filter 연산이 어떻게 이루어지는지.
convolution 연산을 이용합니다.
convolution 연산은 cnn에서 매우 간단하게 수행할 수 있습니다.
아래의 입력 데이터와 filter가 존재한다고 합시다.

즉 각각의 receptive field의 크기를
3X3 크기로 보겠다는 거죠.
아래는 convolution 연산과정.

이런 식으로 receptive field에 다음과 같은 filter로
각각의 weight 값과 픽셀 값을 곱하고 모두 더해 값을 출력합니다
(1*0+0*3+1*2+0*2+1*1+0*0+1*1+0*3+1*2)
이게 cnn에서의 convolution연산입니다.

이런 식으로 모든 receptive field에 대해 동일한 필터로 conv 연산을 진행하여
다음 layer를 구성하는데 이렇게 만들어진 2X2 결과를
feature map이라고 부릅니다
이러한 feature map에는 현재 필터가 찾고자 하는 정보가
어디에서 강하게 나타나는지를 보여줍니다.
현재 2X2의 feature map을 보면 2행 1열의 값이
'10'으로 가장 큰 것을 확인할 수 있습니다.
현재 사용된 필터를 보면

X (모양)<<이미지 정보를 추출하려 하는 필터임을 알 수 있으며 실제로
10이 나온 receptive field를 보면

X (모양)<< 이미지 특성이 어느정도 나타나는 것을 확인해 볼 수 있습니다.
이런 식으로 필터의 weight 구성을 달리한다면
다양한 시각적인 정보를 추출 할 수 있게 됩니다.
가령 아래와 같은 필터를 쓰면 왼쪽 아래로 향하는
대각선의 시각적 정보를 추출하게 됩니다.

이미지 데이터를 학습하는데 다양한 시각적인 정보를 활용한다면
당연히 성능 향상을 기대할 수 있습니다.
이를 위해 여러 개의 필터를 사용해야 하는데
이게 feature map의 개수를 늘려 연산량이 커집니다.
이를 해결하기 위한 방법도 앞으로 다뤄봅니다.
'CNN (Convolutional neural network)' 카테고리의 다른 글
| ResNet이란? (0) | 2025.01.04 |
|---|---|
| GoogLeNet(Inception-v1)이란? (0) | 2024.12.28 |
| CNN의 channal 및 역전파(backpropagation) (1) | 2024.11.30 |
| CNN (Convolutional neural network) (stride, padding ,pooling) (0) | 2024.11.28 |