CNN에서 stride,paddig,pooling이 무엇이며 각각 왜 필요한지 정리합니다.
앞서 cnn에서는 필터의 개수를 많이 할수록
이미지 데이터에서 관측하고자 하는 특징이 많아져
성능이 개선된다고 하였습니다.
2024.11.19 - [데이터 마이닝] - CNN (Convolutional neural network) 이란? (1)
CNN (Convolutional neural network) 이란? (1)
cnn이란?CNN(Convolutional Neural Network)이란,이미지나 영상 데이터를 처리하고 분석하는 데 주로 사용되는인공 신경망의 한 종류입니다. 왜 출현하게 됐는지 정확하게 cnn으로 하고자 하는 게 무엇인
tmddn0512.tistory.com
그런데 필터의 개수가 많아질수록 convolution 연산이 많아져
결과적으로 output인 feature map의 개수가 많아질 수밖에 없습니다.
그래서 연산량이 너무 커지는 문제가 발생합니다.
이를 위한 해결볍으로..
feature map size를 줄이자는 겁니다.
이게 pooling
이전 layer에서 필터와 conv 연산을 해서 나온 feature map의
사이즈 자체를 줄이자는 거죠.
가령 아래와 같이 4x4 크기의 feature map을
2x2 크기로 결과를 요약하자는 겁니다.

feature map이라는 건 어떻게 구성된 거였나요
filter를 이미지 데이터에 조금씩 움직이면서 conv 연산의 결과로 구성된 값입니다.
중요한 것은 이미지 데이터에서 연속적으로 특징을 추출 했다는 것이죠.
즉 featuremap에서 서로 근처에 있는 값들은 비슷한 특징을 가질 거라는 겁니다.
그래서 위의 이미지처럼 요약을 해도 성능이 크게 나빠지지 않습니다.
이때 요약하는 방식에 따라 max pooling, average pooling이라 하는데
이름에서 알 수 있듯 영역 내에서
최댓값을 대푯값으로 요약할 것인지
평균값을 대푯값으로 할 것인지..

max pooling은
이 값의 요약을 최대값인 "9" 로 합니다.
average pooling은
이 값의 요약을 평균인 "3.75" 로 합니다.
어떤 방법이 더 좋을까요
일반적으로 max pooling이 더 좋습니다.
왜냐하면 feature map의 값이 크다는 것은
해당 영역에서 찾고자 하는 특징이 강하게 존재하는 것인데
평균을 내어 대푯값으로 요약해버리면 특징이 희미해질 수 있습니다.
이렇게 feature map의 size를 줄이고도
연산량이 계속해서 많을 수 있습니다.
앞서 말했듯 여러 특징을 잡기 위해 사용하는 필터의 개수가 많기 때문이죠.
이런 경우 convoiution 연산을 할 filter가 움직이는 단위를 크게 합니다.
즉 filter가 움직이는 간격을 키웁니다.

stride=2인 필터의 convolution 연산은
다음 step에서 1칸이 아닌 2칸을 움직여서 연산하게 되는 것이죠.
이미지 데이터는 보통 연속적으로 구성되기 때문에
이렇게 step을 조금 키워도 특징을 놓치지 않습니다.
또 이렇게 필터의 step을 키워야 하는 이유로는..
필터의 사이즈 자체를 키운다면 필터가 이동해야할 step이 적어지지만
필터의 사이즈를 키울 수는 없습니다.
필터의 사이즈가 크면 작은 특징을 놓칠 수 있기 때문.
그래서 step을 키우자는 겁니다.
이런 stride의 크기는 필터의 사이즈보다는 작아야 합니다.
가령 필터가 3X3이라면 stride의 크기는 3보다는 작아야 하는거죠

이유는 왼쪽과 같이 필터에 overlap되는 부분이 존재하지 않으면 그 사이에
존재하는 특징을 놓칠 수 있습니다.
그래서 오른쪽처럼 필터의 overlap이 존재하도록 stride를 키워야 합니다.
zero padding
zero padding 이란?
아래와 같이 기존의 feature map에서
테두리에 0을 채워 넣고 원래 feature map size를
키워 conv 연산을 합니다.

이렇게 하는 이유 첫번째 이유로는
앞서본 pooling이나 stride인수를 도입하면서
featuremap size가 너무 빠르게 줄어들 수 있는데
그걸 방지 합니다.
두번째 이유로는
모서리의 정보를 놓치는 것을 방지합니다.
이게 무슨소리냐면
feature map에 모서리 부분에 존재하는 값이 크다고 생각해 봅시다.
전 layer에서 해당 부분에 대응하는 위치에
찾고자 하는 특징이 있다고 계산이 된 거죠
근데 이때 아래와같이 filter의 weight의 크기가
이 부분에 크게 걸려있다고 가정해봅시다.

그러면 이 filter로는 feature map에 모서리에 있는 특징을 발견하지 못합니다.
이때 아래와 같이 zero padding한 feature map과 filter로 conv연산을 한다면.
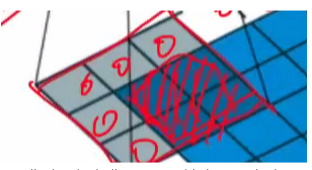
모서리에 있는 정보도 찾을 수 있게 됩니다.
마지막 필터 사이즈에 대해
필터의 사이즈는 홀수 X 홀수를 사용합니다.
홀수를 써야 위치의 중앙이 결정됩니다.
자세히 살펴보면
아래와 같이 홀수인 3X3 필터를 feature map에 적용한다고 했을 때

새로 구성되는 feature map의 원소 하나하나가
이전 이미지의 중앙과 대응합니다.
즉 feature map의 값을 보고 원본 이미지의 위치를 추정할 때
원본 이미지의 중앙과 대응하므로 역추적이 수월합니다.
그래서 홀수를 씁니다.
'CNN (Convolutional neural network)' 카테고리의 다른 글
| ResNet이란? (0) | 2025.01.04 |
|---|---|
| GoogLeNet(Inception-v1)이란? (0) | 2024.12.28 |
| CNN의 channal 및 역전파(backpropagation) (1) | 2024.11.30 |
| CNN (Convolutional neural network) 이란? (1) (0) | 2024.11.19 |