ResNet이란
cnn 기반 모델로써 gradient vanisning 문제 해결 및
optimal depth 문제를 해결하기 위해 사용됩니다.
각각의 문제 상황을 먼저 알아봅시다.
gradient vanishing
gradient 계산을 위해 layer를 걸쳐 chain rule 계산을
아래와 같이 쭉 이어 나가다 보면

0과 1 사이의 값으로 mapping 해주는 활성화 함수(sigmoid) 특성상 그 곱이
0에 가까워져 update가 일어나지 않는 문제가 발생합니다.
물론 relu 활성화 함수로 이것을 어느정도 방지할 수는 있었지만
layer 자체가 과도하게 깊어진다면 vanishing 문제를 본질적으로 해결할 수 없습니다.

optimal depth문제
변수마다 optimal depth가 다를 수 있습니다.
가령 cnn에서 아래와 같이 여러 layer로 이루어진 cnn 모델이 있다고 해봅시다.
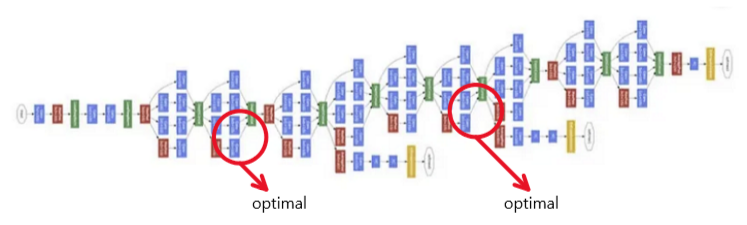
어떤 데이터는 optimal 한 feature가 layer 초반에 나올 수 있습니다.
즉 유의미한 정보가 모든 layer를 다 거치지 않아도 추출될 수 있습니다.
이렇게 추출된 optimal 한 feature에 남은 layer를 거치면서
계속해서 conv 연산을 한다면 유의미한 정보가 왜곡될 수 있습니다.
"즉 data마다 optimal한 depth가 다를 수 있습니다."

따라서 optimal 한 depth가 다르기에 위와 같이
loss가 최적화될 수 있는 포인트가 많아질 수 있습니다.
우선 gradient vanishing 문제 해결을 위해
ResNet은 아래와 같이 구성되어 있습니다.

output을 계산해 나가는 어떤 연산을 F(x)라 합니다.
그리고 output을 계산할 때
깊은 layer에 있는 x를 F(x)에 덧셈으로 값을 가져와 output을 구성하자는 겁니다.
이렇게 현재 layer의 output을 구성할 때에
F(x)를 거치지 않은 x를 연결하면 gradient가 작아지지 않고
gradient가 균일하게 잘 넘어갈 것이라는 것은 쉽게 예측해 볼 수 있습니다.
(미분식이 계속해서 곱으로 이루어지는 것이 아니라 덧셈으로 연결되기 때문)
그래서 gradient를 계산하는 수식을 통해
vanishing 문제를 해결할 수 있는지 직접 증명해 봅시다.
residual connection(+X)이 없을 때 gradient 수식

Error 함수를 weight로 update 한다면 위와 같이 미분합니다.
(Error를 출력값 y로 미분 후 y를 구성하는 x로 y를 미분 후
x를 구성하는 weight로 미분하여 쭉 곱해야 합니다.)
residual connection이 존재하는 경우
출력값 y가 y=F(x)+x이므로
∂y/ ∂w를 아래와 같이 적을 수 있습니다.

그때 기존의 구한 아래 ∂E/ ∂w 식에서

박스 영역에 방금 계산한 ∂y/ ∂w 를 대입한다면 아래와 같습니다.

residual이 존재하는 경우 ∂E/ ∂w 값을 계산할 수 있게 됩니다.
즉 gradient 계산식이 덧셈으로 이루어져 있기에,
gradient vanisning 문제를 어느 정도 해결할 수 있게 됩니다.
또한 optimal depth 문제 해결을 위해 ResNet은 아래와 같이 구성되어 있습니다.

이 skip conncetion이 이미 출력된 optimal feature가
불필요한 conv 연산을 거치지 않게 하는 역할을 하여
모델의 성능을 개선할 수 있습니다.
또한 네트워크가 전체적으로 optimal feature를 뽑도록 하여
Smoothing 된 convex funtion을 뽑을 수 있도록 한다는 장점이 있습니다.

구체적으로 어떻게 가능하게 하는지..
신경망에서 정보가 레이어를 통해 전달될 때
각각 optimal depth가 달라 많은 경우 정보가 왜곡될 수 있습니다.
즉 어떤 데이터는 초기에 출력된 X가 optimal feature일 수 있고
이 x가 F(X)를 거치게 된다면 이 optimal feature가 사라질 수 있습니다.
이로 인해 손실 함수의 표면이 매우 복잡하고 울퉁불퉁해질 수 있습니다.
skip conncetion은 정보가 여러 중간 레이어를 거치지 않고 전달될 수 있게 합니다.
이는 이미 optimal feature인 X가 F(X)를 거치는 걸 skip connection이 막게 됩니다.
결국 네트워크가 훨씬 단순하고 직관적인 변환을 배우도록 합니다.
즉 skip connection을 사용하면 정보가 보다 직선적이고 왜곡 없이 전달되므로,
손실 함수의 표면이 더 매끄럽게 될 수 있습니다.
'CNN (Convolutional neural network)' 카테고리의 다른 글
| GoogLeNet(Inception-v1)이란? (0) | 2024.12.28 |
|---|---|
| CNN의 channal 및 역전파(backpropagation) (1) | 2024.11.30 |
| CNN (Convolutional neural network) (stride, padding ,pooling) (0) | 2024.11.28 |
| CNN (Convolutional neural network) 이란? (1) (0) | 2024.11.19 |